
Ez a bejegyzés a biológia érettségi vizsgakövetelmények 6.1.1.: Molekuláris genetika – Alapfogalmak pontjához nyújt segítséget.
A gének:
Egy olyan hihetetlenül bonyolult és összetett rendszer, mint a testünk működése, kinézete, a tulajdonságaink – kezdve a szemünk színétől, egészen a hormonok komplex működéséig – lenyűgöző módon egy olyan borzasztó egyszerű dologtól függenek, minthogy egy a sejtmagban található nagy molekula (DNS) bizonyos szakaszain 4 primitív molekularészlet (citozin, guanin, adenin és timin) milyen sorrendben követi egymást.
A sejtek, az élőlények működését a gének határozzák meg. A gén nem más, mint a DNS-nek nevezett óriásmolekula egy meghatározott szakasza. A DNS-ben négyféle nukleobázis: citozin, guanin, adenin és timin fordul elő. Az, hogy ezek egymás után hogyan sorakoznak fel a génen, az határozza meg egy bizonyos fehérje szerkezetének kialakulását. A fehérjék pedig az élő szervezetek legfontosabb anyagai, hiszen ezek a vegyületek az élőlények működésének szinte minden területén kulcsfontosságú szerepet játszanak.
(Kattints a képre nagyításhoz!)
Az élőlények génállománya a sejtmagban lévő kromoszómákban található. Az ember esetében ez 23 pár kromoszómát jelent (22 pár testi és 1 pár ivari). Egy-egy kromoszóma tulajdonképpen egy-egy rendkívül hosszú, mégis igencsak kis helyre ,,összecsomagolt” DNS szál. Az összecsomagolásban hisztonoknak nevezett fehérjék is részt vesznek, melyek köré felcsavarodik a DNS kettős spirálja. A gén nem egy tetszőleges molekularészlet, hanem egy olyan pontosan meghatározott szakasza a DNS-nek, amely egy bizonyos fehérje előállításához szükséges információt hordozza. A fajra jellemző összes gén megtalálható az összes sejtjében, de nem mindegyik gén jut minden sejtben kifejeződésre (pl. a kislábujjunk összes sejtjében megtalálhatóak a szemszínünkért felelős gének, de értelemszerűen ott ezeknek nem sok szerep jut). A sejt működéséhez szükséges gének között is van azonban olyan, amely nem folyamatosan működik, hanem csak időszakosan aktiválódik.
Emelt kémia érettségi online tanfolyam
Nézd meg és próbáld ki INGYENESEN a weboldal emelt kémia érettségi online felkészítő tanfolyamát!

Hogyan lesz a gén által kódolt információból működőképes fehérje?
1. Transzkripció
A fehérjék előállításának helyszíne az endoplazmatikus retikulum felszínén található riboszómák. Mivel ezek a kromoszómáktól eltérő helyen vannak a sejtben, így értelemszerűen adódik, hogy a fehérjék szintézise nem közvetlenül a DNS-ről történik, hanem szükség van valamilyen információ-közvetítő anyagra. Itt jön képbe a különböző RNS-ek szerepe.
Amikor egy adott fehérje előállítására szükség van, a megfelelő gén aktiválódik. Ezután egy RNS-polimeráz nevű enzim hozzákapcsolódik a gén elejéhez, melynek ,,megtalálásában” úgynevezett promoter régiók segítik. Ahhoz, hogy az információ eljuthasson a DNS-től a riboszómához, a génről egyfajta másolatot, pontosabban egy átiratot kell készíteni.
A folyamat neve éppen ezért átírás, vagy idegen szóval transzkripció.
Az átirat nem más lesz, mint egy – a DNS-sel ellentétben 1 szálú – nukleinsav: a hírvivő-, vagy messenger-RNS. A folyamat során az RNS-polimeráz halad előre a génen, s eközben szabad nukleotidokból összeállva, a DNS egyik száláról készül az átirat, a bázispárosodás szabályainak megfelelően (A-T, U-A, G-C, C-G).
Ahhoz, hogy átirat képződhessen az egyik szálról, helyet kell csinálni a készülő m-RNS-nek, vagyis a DNS szálnak lokálisan ketté kell nyílnia. (Ezt úgy lehet elképzelni, mint egy rossz cipzárat, amely behúzott állapotban egy szakaszon kettéválik). Azt a szálat, amelyről a másolat készül templát, vagy antiszensz szálnak nevezzük. Ez a kettényílt állapot a DNS-nek nem kedvező, ezért mindig csak azon a rövid szakaszon válik ketté, ahol éppen az RNS-polimeráz enzim jár. Ahogy átírta a gén egy szakaszát a m-RNS-be, és túlhalad azon, mögötte azonnal záródik a ,,cipzár”.
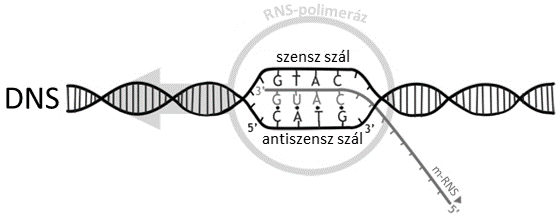
(Forrás: https://commons.wikimedia.org/wiki/File:DNA_transcription.jpg ; Dovelike; CC 3.0 )
(Kattints a képre nagyításhoz!)
Az elkészült m-RNS egy utólagos érési folyamaton esik keresztül, mielőtt a fehérjeszintézis helyére ,,vándorolna”. Ennek során leggyakrabban bizonyos szakaszok, úgynevezett intronok hasadnak ki a molekulából. Eukarióta sejtekben más-más sejttípusban más-más szakaszok hasadhatnak ki. Ennek az az eredménye, hogy
különböző szövetekben ugyanarról a génről más-más érett m-RNS készülhet, ennek következtében pedig más-más fehérje szintetizálódhat arról. Ez az eukarióták bonyolultságának egyik kulcstényezője.
A genetikai kód
Az elkészült, érett m-RNS most már készen áll arra, hogy a riboszómához kapcsolódva bázissorrendje az elkészítendő fehérje ,,receptjéül” szolgáljon. Van itt azonban egy kis probléma: a fehérjék aminosavakból épülnek fel, és elsődlegesen az aminosavsorrendjük határozza meg őket. Vagyis a m-RNS bázissorrendjét aminosavsorrendre kell átfordítani. A folyamat neve nem véletlenül átfordítás, vagy transzláció (akárcsak mintha mondjuk angolról magyarra fordítanánk egy szöveget, csak itt éppen bázisokról aminosavakra fordítunk).
A bökkenő ott van, hogy nukleobázisból összesen 4 féle van a m-RNS-ben, az élővilág fehérjéit pedig 20 féle aminosav építi fel. Mit lehet tenni? Kódoljon mondjuk 2 bázis egy aminosavat! Ekkor 42, azaz 16 féle aminosav kódolására van lehetőség. Ez még mindig nem elég 20-hoz. Viszont, ha 3 bázis kódol egy aminosavat, akkor 43 = 64 féle aminosav kódolása lehetséges. Ez lesz a megoldás! Nem baj, hogy elvben így sokkal több aminosav kódolására van lehetőség, pusztán annyi fog történni, hogy egy aminosavat több bázishármas is kódolhat (ezt nevezik a genetikai kód redundáns vagy degenerált jellegének).
A genetikai kódot tehát végső soron a DNS-ben egymást követő bázis tripletek alkotják, melyek a m-RNS-be átírva 1-1 aminosav fehérjébe épüléséért felelősek. Az aminosavat kódoló tripletet kodonnak nevezünk.
A kód univerzális, azaz az egész élővilágban ugyanaz a bázishármas ugyanazt az aminosavat kódolja. Ez az élet közös eredetének egyik legjelentősebb bizonyítéka!
2. Transzláció
A transzláció első lépéseként a riboszóma ,,megkeresi” a legelső kodont az érett m-RNS-en. Ez minden egyes fehérje szintézisekor az AUG jelű, amely a metionin nevű aminosavat kódolja. Ezt a kodont ezért START kodonnak is nevezik. Ezután következhet a többi kodonnak a leolvasása, egyszerre mindig egynek. Különösen fontos, hogy a leolvasás pontosan a START kodonnál kezdődjön, hiszen a genetikai kód leolvasása kihagyás-, és átfedésmentes. Vagyis az egyes kodonok közvetlenül egymás után sorakoznak fel, és mindhárom bázisuk csak egy leolvasási lépésben vesz részt. Tehát pl. ha az AUGGGCAGC… kezdetű fehérje szintézise nem a piros A-nál, hanem a piros U-nál kezdődne, akkor a szekvencia már: AUGGGCAGC… lenne, amely működésképtelen fehérje létrejöttét eredményezné.
Ebből az is látszik, hogy miért probléma egy mutáció során bekövetkező bázis ,,kiesése”, vagy bázisok felcserélődése a DNS-ben: a megváltozott szekvencia borítja egy ponton az egész leolvasást, az így létrejövő hibás fehérje pedig nem tudja ellátni a feladatát, amely általában ártalmas következménnyel: genetikai betegséggel járhat együtt.
Azt, hogy melyik kodon melyik aminosavat jelöli, azt az úgynevezett kodonszótár mutatja meg. Az AUG jelű kodon, amely tehát a metionint jelöli, egyben minden fehérjeszintéziskor a START kodon is. Három kodon, az UAA, UAG, és a UGA nem kódol aminosavat. Ezek STOP kodonok, vagyis a fehérjeszintézis végét jelzik.

(Kattints a képre nagyításhoz!)
Transzfer-RNS-ek szállítják a kodon által meghatározott aminosavakat a riboszómához. Csak olyan t-RNS által szállított aminosav tud a peptidláncba épülni, amelynek az őt szállító t-RNS-ének m-RNS kötőhelye, vagy más szóval antikodonja (a bázispárosodás szabályainak megfelelően) az éppen leolvasott kodon komplementere. Ha az adott t-RNS kielégíti ezt a feltételt, akkor ,,odafér” a riboszómához, így az általa szállított aminosav térben megfelelően közel tud kerülni a készülő peptidlánc növekvő végéhez, s így az aminosavnak lehetősége van kovalens kötés létesítésére a lánccal. A peptidláncnak mindig a C-terminális vége a növekvő vég. Amint az utolsó aminosav is kialakította a peptidkötést, a lánc leválik a riboszómáról, és végleges térbeli konformációjának elnyerése után elkészült a fehérje.
A DNS-től a fehérjéig:
A teljes folyamatot a yourgenome látványos 3D animációja kitűnően szemlélteti:
Egy hasonlat
A teljes folyamat lényegét a következő kis óvodás hasonlattal tudnám szemléltetni: Van egy könyvtár (sejtmag), ahol egy 46 kötetből álló receptes gyűjtemény (23 pár kromoszóma) tartalmazza az összes olyan étel (fehérjék) receptjét (gének), amelyeket annyira szeretünk, hogy szinte élni sem tudnánk nélkülük. Mivel ezek rendkívül fontos könyvek, ha bármi történne velük (mutáció), például kiszakadna egy lap, az végzetes veszteség lenne, ezért nem lehet kikölcsönözni őket. Ha főzni szeretnénk valamelyik recept alapján, még a könyvtárban le kell fénymásolnunk az adott oldalakat (átírás). A fénymásolásban segít nekünk a könyvtáros (RNS-polimeráz enzim). A lefénymásolt receptet (m-RNS) már el lehet vinni a könyvtárból a konyhába (endoplazmatikus retikulum), és a szakács (riboszóma) elkészítheti az ételt (fehérje) az alapján. A recept angolul (bázis-ul) van, de a szakács csak magyarul (aminosav-ul) tud, így le kell fordítani azt (transzláció). A szakácsnak specifikus fordítói vannak, minden hozzávalót (aminosavak) csak 1 fordító (t-RNS) tud lefordítani, és egyúttal viszi is magával azt a szakácsnak. Ahhoz, hogy az étel ehető legyen (működőképes fehérje), fontos, hogy a hozzávalókat a receptben leírtaknak megfelelő sorrendben (aminosav sorrend) adjuk hozzá!